7.1 전체 구조
2.1.1 소제목
- 완전연결(fully-connected, 전결합, 지금까지 본 신경망)
- Affine 계층

- CNN (합성곱 계층 Conv와 풀링 계층 Pooling이 새로 추가)
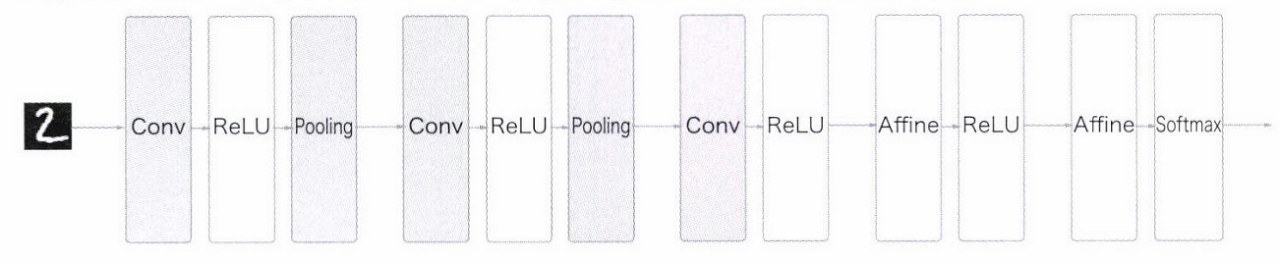
-> 지금까지의 Affine-ReLU 연길이 Conv-ReLU로 바뀜
-> 출력에 가까운 층에서는 Affine-ReLU 구성 사용
-> 출력 계층에서는 Affine-Softmax 조합 그대로 사용
7.2 합성곱 계층
7.2.1 완전연결 계층의 문제점
- 데이터의 형상이 무시됨
- 3차원 데이터인 이미지 데이터를 평평한 1차원 데이터로 평탄화
- 공간적 정보 무시
-> 합성곱 계층은 형상 유지
- CNN에서는 입출력 데이터를 특징 맵(feature map)이라고 함
7.2.2 합성곱 연산
: 필터 연산

- 입력 데이터와 필터 모두 세로, 가로 방향의 차원을 가짐
- 형상 : (높이, 너비)로 표기
- 입력 데이터(4,4), 필터(3,3)
- 연산
- 1) 윈도우를 일정 간격으로 이동해가며 입력 데이터에 적용
- 2) 대응하는 원소끼리 곱하기
- 3) 총합 구하기 (단일 곱셈-누산 계산 방법 :fused multiply-add)
- 4) 총합 결과를 출력의 해당 장소에 저장
- 5) 모든 장소에서 계산을 수행하면 합성곱 연산 출력 완성
- 필터의 매개변수 = 그동안의 가중치

- 편향 - 필터를 적용한 후의 데이터에 더해짐
- 항상 하나(1x1)만 존재
- 필터를 적용한 모든 원소에 더함
7.2.3 패딩
padding: 입력 데이터 주변을 특정 값(ex: 0)으로 채우는 것

- 입력 데이터에 폭이 1인 패딩을 적용한 것
- 입력 데이터 (4,4) -> (6,6)
- 출력 데이터 (4,4)
-> 출력 크기를 조정할 목적
7.2.4 스트라이드
stride: 필터를 적용하는 위치의 간격

->스트라이드를 키우면 출력 크기는 작아짐
-> 패딩을 키우면 출력 크기 커짐
- 출력 크기 계산 수식화
- 입력 크기 (H, W) , 필터 크기 (FH, FW), 출력 크기 (OH, OW), 패딩 P, 스트라이드 S

7.2.5 3차원 데이터의 합성곱 연산
- 이미지 - 세로, 가로, 채널까지 고려한 3차원 데이터

-> 입력 데이터와 필터의 합성곱 연산을 채널마다 수행하고, 그 결과를 더해서 하나의 출력
- 입력 데이터의 채널 수와 필터의 채널 수 같아야 함
7.2.6 블록으로 생각하기
- 3차원 데이터 (채널, 높이, 너비)

-> 출력 데이터도 3차원으로 하려면 필터를 다수 사용

-> 필터를 FN개 적용하면 출력 맵도 FN개 생성 (FN, OH, OW)
- 필터의 가중치 데이터는 4차원 데이터 (출력 채널 수 (채널 개수), 입력 채널 수, 높이, 너비)

-> 편향 추가
편향 형상 : (FN, 1, 1)
7.2.7 배치 처리
- 각 계층을 흐르는 데이터의 차원을 하나 늘려 4차원 데이터로 저장
- (데이터 수, 채널 수, 높이, 너비)

-> 4차원 데이터가 하나 흐를 떄마다 데이터 N개에 대한 합성곱 연산
=> N회 분의 처리 한 번에 수행
7.3 풀링 계층
풀링 : 세로, 가로 방향의 공간을 줄이는 연산
- 예) 2*2 최대 풀링 (max pooling)

- 2*2 영역에서 가장 큰 원소 하나를 꺼냄
- 스트라이드 대로 이동
- 풀링의 윈도우 크기와 스트라이드는 같은 값으로 설정하는 것이 보통
- 최대 풀링 외에도 평균 풀링 등이 있음
- 이미지 인식 분야에서는 주로 최대 풀링 사용
7.3.1 풀링 계층의 특징
- 학습해야 할 매개변수가 없다.
- 채널 수가 변하지 않는다. (입력 데이터의 채널 수 그대로 출력 데이터로 내보냄, 채널마다 독립적으로 계산)
- 입력의 변화에 영향을 적게 받는다 (강건하다)
- 입력데이터가 조금 변해도 풀링의 결과는 잘 변하지 않음
7.4 합성곱 / 풀링 계층 구현하기
7.4.1 4차원 배열
##4차원 배열
x = np.random.rand(10, 1, 28, 28) #높이 28, 너비 28, 채널 1개인 데이터 10개 랜덤으로 생성
print(x.shape)
print(x)
#10개 중 첫번째 데이터에 접근
print(x[0].shape) #(1, 28, 28)
print(x[1].shape) #(1, 28, 28)
#첫번째 데이터의 첫 채널의 공간 데이터에 접근
x[0,0]- np.random.randint : 균일 분포의 정수 난수 1개 생성
- np.random.rand : 0부터 1사이의 균일 분포에서 난수 행렬 생성
- np.random.randn : 가우시안 표준 정규 분포에서 난수 행렬 생성
7.4.2 im2col로 데이터 전개하기
- 합성곱 연산 - for 문 사용하면 성능이 떨어지고 복잡함
-> im2col 함수 사용 (image to column) - im2col : 입력 데이터를 필터링(가중치 계산)하기 좋게 전개하는 함수
-> 4챠원 데이터를 2차원으로 변환

- 메모리를 더 많이 소비하는 단점
- 하지만 행렬 계산에 고도로 최적화되어 큰 행렬의 곱셈을 빠르게 계산할 수 있는 선형 대수 라이브러리 활용해 효율 높일 수 있음

- im2col로 입력 데이터 전개 -> 합성곱 계층의 필터 (가중치) 1열로 전개 -> 행렬 곱 : Affine 계층과 비슷함
- 2차원 출력 데이터를 4차원으로 변형 (reshape)
7.4.3 합성곱 계층 구현하기
- im2col 함수의 인터페이스
im2col(input_data, filter_h, filter_w, stride = 1, pad = 0)- input_data : (데이터 수 , 채널수, 높이, 너비)의 4차원 배열 입력 데이터
- filter_h : 필터의 높이
- filter_w : 필터의 너비
- stride : 스트라이드
- pad : 패딩
##합성곱 계층 구현하기
#im2col 사용
x1 = np.random.rand(1,3,7,7) #(데이터수, 채널수, 높이, 너비)
col1 = im2col(x1, 5, 5, stride=1, pad=0)
print(col1.shape) #(9, 75) -> 75: 필터의 원소 수 5(필터높이)*5(필터너비)*3(채널수)
x2 = np.random.rand(10,3,7,7) #데이터 10개
col2 = im2col(x2, 5,5, stride=1, pad=0)
print(col2.shape) #(90,75) -> 90: 배치 10이므로 배치 1일 때 9*10class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self,x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int(1+(H+2*self.pad -FH) / self.stride)
out_W = int(1+(W+2*self.pad-FW)/ self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T #필터 전개
#(정수, -1) : 다차원 배열의 원소 수가 변환 후에도 유지되도록 적절히 묶어줌
# -> (정수, 적절한 묶음 수) ex: 750개 원소 - reshape(10,-1) -> (10,75)
#T 메소드 : 행과 열을 바꿔주는 메소드, 세로로 전개하기 위해 ex:(2,3) -> (3,2)
out = np.dot(col, col_W) +self.b
out = out.reshape(N, out_h, out_W, -1).transpose(0,3,1,2)
#출력 데이터를 적절한 형상으로 바꿔주기
#transpose메소드 : 인덱스를 지정하여 다차원 배열의 축 순서 바꿔주는 함수
#-> (N, C(-1), out_h, out_W)
return out- 입력 데이터 im2col로 전개
- 필터 reshape로 세로로 전개
- 행렬곱
- 출력 데이터 형상 바꾸기
7.4.4 풀링 계층 구현하기
- 채널마다 독립적으로 전개

##풀링 계층 구현하기
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1+(H-self.pool_h)/self.stride)
out_w = int(1+(W-self.pool_w)/self.stride)
#전개
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
#shape를 (적절한묶음, 풀영역원소개수)로 바꿔줌
#최댓값
out = np.max(col, axis = 1) #행별 최댓값
#성형
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
return out- 입력 데이터 전개
- 행별 최댓값 구하기
- 적절한 모양으로 성형
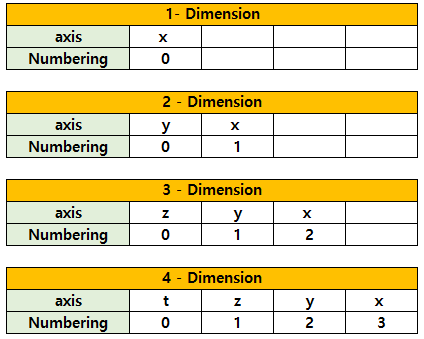
+) 참고 : 차원별 축 넘버링
7.5 CNN 구현하기

초기화 때 받는 인수
- input_dim : 입력 데이터 (채널 수 , 높이, 너비) 차원
- conv_param: 합성곱 계층의 하이퍼파라미터(딕셔너리)
- filter_num : 필터 수
- filter_size : 필터 크기
- stride : 스트라이드
- pad : 패딩
- hidden_size : 은닉층의 뉴런 수
- output_size : 출력층의 뉴런 수
- weight_init_std : 초기화 때의 가중치 표준편차
class SimpleConvNet:
def __init__(self, input_dim=(1, 28,28),
conv_param={'filter_num':30, 'filter_size':5,'pad':0, 'stride':1},
hidden_size =100, output_size=10,weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1] #(높이, 너비)
conv_output_size = (input_size - filter_size +2*filter_pad)/ filter_stride+1 #합성곱 계층의 출력 크기 계산
pool_output_size = int(filter_num*(conv_output_size/2)*(conv_output_size/2))
#가중치 매개변수 초기화
self.params = {}
self.params['W1']= weight_init_std*np.random.randn(filter_num, input_dim[0], filter_size, filter_size) #합성곱계층 가중치
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std*np.random.randn(pool_output_size, hidden_size) #완전연결계층 가중치
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std*np.random.randn(hidden_size, output_size) #2완전연결계층 가중치
self.params['b3'] = np.zeros(output_size)
#CNN 구성 계층
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
#추론 수행
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
#손실 함수
def loss(self, x, t):
y = self.predict(x)
return self.last_layer.forward(y, t)
#기울기 구하기
def gradient(self, x, t):
#순전파
self.loss(x, t)
#역전파
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
#결과 저장
grads = {}
grads['W1'] = self.layers['Conv1'].dW
grads['b1'] = self.layers['Conv1'].db
grads['W2'] = self.layers['Affine1'].dW
grads['b2'] = self.layers['Affine1'].db
grads['W3'] = self.layers['Affine2'].dW
grads['b3'] = self.layers['Affine2'].db
return grads
- MNIST 데이터셋 학습 결과

epoch:20, train acc:0.994, test acc:0.966
test acc:0.964
*책에서는 98.96% (학습별로 정확도에는 약간의 오차 발생)
7.6 CNN 시각화하기
7.6.1 1번째 층의 가중치 시각화하기
- MNIST 데이터셋 CNN 학습에서 1번째 층의 합성곱 계층의 가중치 형상 : (30,1, 5, 5) -> 필터의 크기가 5*5이고 채널이 1개
=> 1채널의 회색조 이미지
##1번째 층의 가중치 시각화하기
def filter_show(filters, nx=8, margin=3, scale=10):
"""
c.f. https://gist.github.com/aidiary/07d530d5e08011832b12#file-draw_weight-py
"""
FN, C, FH, FW = filters.shape
ny = int(np.ceil(FN / nx))
fig = plt.figure()
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(FN):
ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[])
ax.imshow(filters[i, 0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
network = SimpleConvNet()
# 무작위(랜덤) 초기화 후의 가중치
filter_show(network.params['W1'])
# 학습된 가중치
network.load_params("params.pkl")
filter_show(network.params['W1'])- 가중치의 원소는 실수이지만, 이미지에서는 가장 작은 값(0)은 검은색, 가장 큰 값(255)은 흰색으로 정규화하여 표시함


- 학습 전 필터는 무작위로 초기화되어 흑백의 정도에 규칙성 x
- 학습 후 필터는 규칙성이 생김 (흰색에서 검은색으로 점차 변화하는 필터와 덩어리(블롭 blob)가 진 필터 등)
- 필터는 에지(색상이 바뀐 경계선)와 블롭(국소적으로 덩어리진 영역) 등을 보고 있음
-> 원시적인 정보 추출 - 구현한 CNN에서 원시적인 정보가 뒷단 계층에 전달됨
7.6.2 층 깊이에 따른 추출 정보 변화
- 계층이 깊어질수록 추출되는 정보는 더 추상화
- 처음 층 : 단순한 에지에 반응 -> 텍스처에 반응 -> 더 복잡한 사물의 일부에 반응 -> 사물 분류 (의미 이해)
- 층이 깊어지면서 뉴런이 반응하는 대상이 단순한 모양에서 고급 정보로 변화
7.7 대표적인 CNN
7.7.1 LeNet
- 손글씨 숫자를 인식하는 네트워크, 1998년에 제안
- 합성곱 계층과 풀링 계층(단순히 원소를 줄이기만 하는 서브샘플링 계층)을 반복 후 완전연결 계층을 거치면서 결과 출력
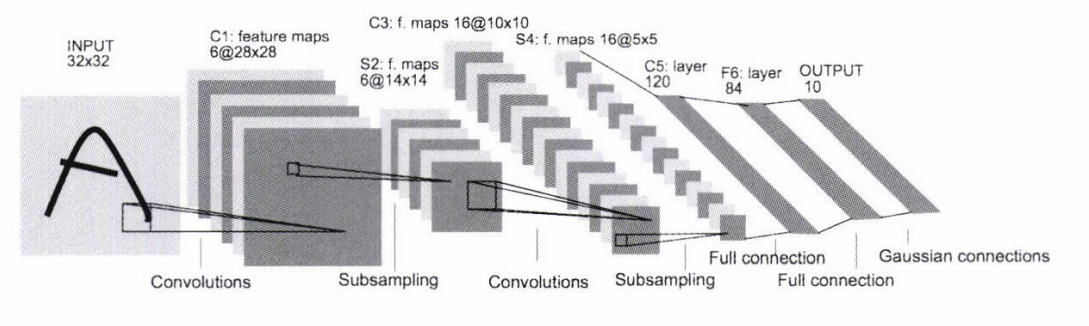
- 현재의 CNN과 다른 점
- LeNet : 시그모이드 함수 / 현재 : ReLU함수
- LeNet : 서브샘플링(중간 데이터 크기 줄임) / 현재 : 최대 풀링
-> 큰 차이는 아님
7.7.2 AlexNet

- 합성곱 계층과 풀링 계층을 거듭하며 마지막으로 완전연결 계층을 거쳐 결과 출력
- LeNet에서 변화된 것
- 활성화 함수로 ReLU 이용
- LRN(Local Response Normalization)이라는 국소적 정규화를 실시하는 계층 이용
- 드롭아웃 사용
- 병렬 계산에 특화된 GPU와 빅데이터가 딥러닝 발전의 큰 원동력이 됨
7.8 정리
- CNN은 지금까지의 완전연결 계층 네트워크에 합성곱 계층과 풀링 계층을 새로 추가한다.
- 합성곱 계층과 풀링 계층은 im2col을 이용하면 간단하고 효율적으로 구현할 수 있다.
- CNN을 시각화해보면 계층이 깊어질수록 고급 정보가 추출되는 모습을 확인할 수 있다.
- 대표적인 CNN에는 LeNet과 AlexNet이 있다.
- 딥러닝의 발전에는 빅데이터와 GPU가 크게 기여했다.
책 참고 : 밑바닥부터 시작하는 딥러닝 (한빛미디어)
'딥러닝 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| 8장 : 딥러닝 (0) | 2023.09.19 |
|---|---|
| 6장 : 학습 관련 기술들 (0) | 2023.09.15 |
| 5장 : 오차역전파법 (0) | 2023.09.13 |
| 4장 : 신경망 학습 (0) | 2023.09.06 |
| 3장 : 신경망 (0) | 2023.09.05 |



