- 퍼셉트론의 가중치 - 사람이 수동적으로 설정해야 함
- 신경망 : 가중치 매개변수의 적절한 값을 데이터로부터 자동으로 학습하는 능력
- 신경망이 입력 데이터가 무엇인지 식별하는 처리 과정 : 활성화 함수
3.1 퍼셉트론에서 신경망으로
3.1.3 활성화 함수
: 입력 신호의 총합을 출력 신호로 변환하는 함수
- 입력 신호의 총합이 활성화를 일으키는 지 정하는 역할
- 단순 퍼셉트론 : 단층 네트워크에서 계단 함수를 활성화 함수로 사용한 모델
- 다층 퍼셉트론 : 신경망 (여러 층으로 구성, 시그모이드 함수 등의 매끈한 활성화 함수 사용하는 네트워크)
3.2 활성화 함수
3.2.1 시그모이드 함수

참고: https://gooopy.tistory.com/52
3.2.2 계단 함수 구현
import numpy as np
import matplotlib.pylab as plt
#계단 함수 정의
def step_function(x):
y = x > 0
return y.astype(np.int)
x = np.arange(-5.0, 5.0, 0.1) #-5에서 5 사이 0.1간격의 넘파이 배열
y = step_function(x)
#그래프
plt.plot(x,y)
plt.ylim(-0.1, 1.1) #y축의 범위 지정
plt.show()- 계단 함수
- y : 0보다 크면 True, 작으면 False -> int로 변환 (true는 1, false는 0)

3.2.4 시그모이드 함수 구현
#시그모이드 함수 정의
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
#그래프
plt.plot(x,y)
plt.ylim(-0.1, 1.1)
plt.show- 시그모이드 함수
- np.exp(-x) : exp(-x) 수식
- x가 넘파이 배열이어도 처리 가능
- S자 모양

3.2.5 시그모이드 함수와 계단 함수 비교
- 차이점
- 계단 : 0과 1 중 하나의 값만 출력
- 시그모이드 : 연속적인 실수(0.731...0.880)를 출력
- 공통점
- 입력이 작을 때의 출력은 0에 가깝거나 0
- 입력이 클 때의 출력은 1에 가깝거나 1
3.2.6 비선형 함수
- 신경망에서는 활성화 함수로 비선형 함수를 사용해야 함
- 선형 함수를 이용해서는 여러 층으로 구성하는 이점을 살릴 수 없기 때문
3.2.7 ReLU 함수
: 입력이 0을 넘으면 그 입력을 그대로 출력, 0 이하이면 0을 출력하는 함수

def relu(x):
return np.maximum(0,x)- maximum 함수 : 두 입력 중 큰 값을 선택해 반환
3.3 다차원 배열의 계산
3.3.1 다차원 배열
#1차원
A = np.array([1,2,3,4])
print(A)
print(np.ndim(A)) #차원 수 확인
print(A.shape)
print(A.shape[0])[1 2 3 4]
1
(4,)
4
#2차원 (행렬)
B = np.array([[1,2], [3,4], [5,6]])
print(B)
print(np.ndim(B))
print(B.shape)[[1 2]
[3 4]
[5 6]]
2
(3, 2) #행/열
3.3.2 행렬의 곱
#행렬의 곱
A = np.array([[1,2], [3,4]])
B = np.array([[5,6],[7,8]])
np.dot(A,B)array([[19, 22],
[43, 50]])
#형상이 다른 행렬의 곱
A = np.array([[1,2,3], [4,5,6]]) #2*3
B = np.array([[1,2],[3,4], [5,6]]) #3*2
np.dot(A,B)array([[22, 28],
[49, 64]])
- 행렬 A의 1번째 차원의 원소 수 (열 수)와 행렬 B의 0번째 차원의 원소 수(행 수)가 같아야 함( 2*3 / 3*2)
- 계산 결과 : 행렬 A의 행 수와 행렬 B의 열수 (2*3 / 3*2)
3.3.3 신경망에서의 행렬 곱
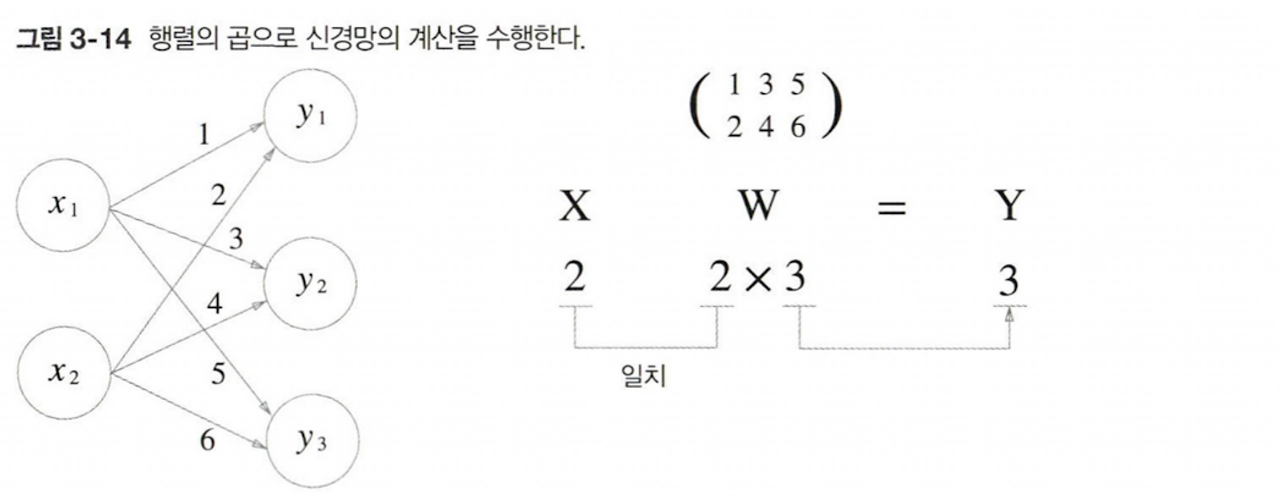
X = np.array([1,2]) #입력값
W = np.array([[1,3,5], [2,4,6]]) #가중치
Y = np.dot(X,W) #출력값
print(Y)[ 5 11 17]
- 편향과 활성화 함수는 생략
3.4 3층 신경망 구현하기

def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) #1층 가중치
network['b1'] = np.array([0.1, 0.2, 0.3]) #1층 편향
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) #2층 가중치
network['b2'] = np.array([0.1,0.2]) #2층 편향
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]]) #3층 가중치
network['b3'] = np.array([0.1, 0.2]) #3층 편향
return network
def forward(network, x):
W1, W2, W3 = network["W1"], network['W2'], network['W3']
b1, b2, b3 = network["b1"], network['b2'], network['b3']
a1 = np.dot(x, W1) +b1 #입력값*가중치 +편향
z1 = sigmoid(a1) #1층 활성화함수 출력값
a2 = np.dot(z1, W2) +b2 #2층
z2 = sigmoid(a2) #2층 활성화함수 출력값
a3 = np.dot(z2, W3) +b3 #3층
y = a3 #출력층 활성화 함수로 항등함수 사용
return y
network = init_network()
x = np.array([1.0, 0.5]) #입력값
y = forward(network, x)
print(y)[0.31682708 0.69627909]
3.5 출력층 설계하기
기계학습
- 분류 -> 소프트맥스 함수
- 회귀 -> 항등 함수
소프트맥스 함수 : https://gooopy.tistory.com/53
3.5.2 소프트맥스 함수 구현 시 주의점
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c) #오버플로 대책
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y- 지수함수 exp()는 큰 값을 출력 -> 큰 값끼리 나눗셈 하면 결과 수치 불안정 : 오버플로 문제
- 오버플로 : 컴퓨터는 표현할 수 있는 수의 범위 한정, 너무 큰 값 표현할 수 없음
- 소프트맥스 함수의 지수 함수는 어떤 정수를 빼거나 더해도 결과 바뀌지 않음
- 입력 신호 중 최댓값을 빼는 것이 일반적 (a-c)
3.5.3 소프트맥스 함수의 특징
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y)
np.sum(y)[0.01821127 0.24519181 0.73659691]
1.0
- 0에서 1.0 사이의 실수 출력
- 출력의 총합 1 -> 확률로 해석 가능
- 원소의 대소 관계는 변하지 않음 (입력값이 크면 출력값도 큼)
-> 추론 단계에서는 출력층의 소프트맥스 함수 생략
- 학습시킬 때는 사용
3.5.4 출력층의 뉴런 수 정하기
- 분류 : 분류하고 싶은 클래스 수로 설정하는 것이 일반적
3.6 손글씨 숫자 인식
3.6.1 MNIST 데이터셋
- 데이터셋 py 다운 후 구글드라이브에 업로드
- 구글 드라이브 마운트
import sys, os
sys.path.append("/content/drive/MyDrive/Colab Notebooks/밑바닥딥러닝/dataset") #파일 경로
from mnist import load_mnist ##mnist.py파일에 정의된 load_mnist()함수 이용#다운로드
(X_train, t_train), (X_test, t_test) = \ #(훈련이미지, 훈련레이블), (시험이미지, 시험레이블)
load_mnist(flatten=True, normalize=False)load_mnist의 인수
- nomalize(정규화) : 입력 이미지의 픽셀 값을 0.0~1.0 사이의 값으로 정규화 (false : 원래 값인 0~255) -> 전처리
- flatten : 입력 이미지를 1차원 배열로 만듦 (True: 784, false : 1*28*28)
- one_hot_label : 원-핫 인코딩 = 정답을 뜻하는 원소만 1, 나머지는 모두 0
img = X_train[0] #첫번째 훈련 이미지
label = t_train[0]
print(label) #5print(img.shape) #flatten 결과 (784,)
img = img.reshape(28,28)
print(img.shape)
3.6.2 신경망의 추론 처리
import numpy as np
import pickle #프로그램 실행 중에 특정 객체를 파일로 저장, 데이터 빠르게 준비 가능
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("/content/drive/MyDrive/Colab Notebooks/밑바닥딥러닝/dataset/sample_weight.pkl", 'rb') as f:
network = pickle.load(f) #학습된 가중치 매개변수: 가중치, 편향 매개변수가 딕셔너리 변수로 되어 있음
return network
def predict(network, x):
W1, W2, W3 = network["W1"], network['W2'], network['W3']
b1, b2, b3 = network["b1"], network['b2'], network['b3']
a1 = np.dot(x, W1) +b1 #입력값*가중치 +편향
z1 = sigmoid(a1) #1층 활성화함수 출력값
a2 = np.dot(z1, W2) +b2 #2층
z2 = sigmoid(a2) #2층 활성화함수 출력값
a3 = np.dot(z2, W3) +b3 #3층
y = softmax(a3)
return y#정확도 평가
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) #확률이 가장 높은 원소의 인덱스
if p == t[i]:
accuracy_cnt +=1
print("Accuracy:" +str(float(accuracy_cnt / len(x)))) #정확도 : 맞힌 횟수 / 전체 이미지 숫자Accuracy:0.9352
3.6.3 배치 처리
- 배치 : 하나로 묶은 입력 데이터, 배치가 곧 묶음
- 컴퓨터에서는 큰 배열을 한꺼번에 계산하는 것이 분할된 작은 배열을 여러 번 계산하는 것보다 빠름
-> 배치 처리로 큰 배열로 이뤄진 계산
#배치 처리
x, t = get_data()
network = init_network()
batch_size = 100 #배치 크기
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1) #axis=1 : 행을 따라 최대값, axis=0 :열을 따라 최대값
accuracy_cnt +=np.sum(p==t[i:i+batch_size]) #True인, p와 t가 같은 개수 셈
print("Accuray:" + str(float(accuracy_cnt)/len(x)))3.7 정리
- 신경망에서는 활성화 함수로 Sigmoid와 ReLU 같은 매끄럽게 변화하는 함수를 이용한다.
- Numpy의 다차원 배열을 잘 사용하면, 신경망을 효율적으로 구현할 수 있다.
- 기계학습 문제는 크게 회귀와 분류로 나눌 수 있다.
- 출력층의 활성화 함수로는 회귀에서 주로 항등함수를, 분류에서는 주로 소프트맥스 함수를 이용한다.
- 분류에서는 출력층의 뉴런 수를 분류하려는 클래스 수와 같게 설정한다.
- 입력 데이터를 묶은 것을 배치라 하며, 추론 처리를 이 배치 단위로 진행하면 결과를 훨씬 빠르게 얻을 수 있다.
책 참고 : 밑바닥부터 시작하는 딥러닝 (한빛미디어)
'딥러닝 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| 6장 : 학습 관련 기술들 (0) | 2023.09.15 |
|---|---|
| 5장 : 오차역전파법 (0) | 2023.09.13 |
| 4장 : 신경망 학습 (0) | 2023.09.06 |
| 2장 : 퍼셉트론 (0) | 2023.09.04 |
| 1장 : 헬로 파이썬 (0) | 2023.09.02 |


