6.1 매개변수 갱신
최적화 : 손실 함수의 값을 가능한 한 낮추는 최적의 매개변수를 찾는 것
6.1.2 확률적 경사 하강법(SGD)

#SGD
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr*grads[key]- params 매개변수들에 대해 learning rate * key에 대한 gradient만큼 빼주는 방법
6.1.3 SGD의 단점
- 비효율적
- 현재 장소에서 기울어진 방향을 따라서 이동하는데, 현재 위치에서 기울어진 방향이 global minimum의 방향과 차이가 날 수 있어서 지그재그를 그리면서 비효율적인 경로를 따라 움직임 (비등방성 함수)

6.1.4 모멘텀

- v 새로운 변수 : 속도 - 기울기 방향으로 힘을 받아 물체가 가속된다는 물리 법칙
- Loss function에서 기울기가 가파르면 v가 커지고 기울기가 완만하면 v가 작아짐
- SGD에서는 loss function의 기울기에 따라 W를 update 하는 비율이 learning rate로 일정
- 모멘텀에서는 loss function의 기울기에 따라 W를 update 하는 비율이 달라짐
- v가 크면 W가 크게 움직이고 v가 작으면 W가 조금 움직임
#모멘텀
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
#params딕셔너리 변수의 key에 저장된 val과 같은 형태의 행렬을 만들고 그 행렬을 0으로 채운뒤, v라는 딕셔너리 변수에 저장
#초기 한번만 실행
#v를 갱신한 뒤, 가중치에 대해 갱신
for key in params.key():
self.v[key] = (self.momentum*self.v[key]) - (self.lr*grads[key])
params[key]+=self.v[key]
- SGD와 비교했을 때, 지그재그 정도가 덜함
- f(x,y)의 기울기가 x축은 완만하고 y축은 가파르게 변함
- x축은 일정한 방향으로 가속하고 y축의 방향 속도는 일정하지 않아서 x축으로 빠르게 다가감 -> SGD보다 효율적
6.1.5 AdaGrad
- 신경망 학습에서 학습률 값이 중요
- 학습률을 정하는 효과적 기술 :학습률 감소
- 학습을 진행하면서 학습률을 점차 줄여가는 방법
- 전체의 학습률 값을 각각의 매개변수에 맞게 낮추는 방법 : AdaGrad

- h 새로운 변수 : 기존 기울기 값을 제곱하여 계속 더해줌
- 학습률에 1/√h를 곱해줌
-> L의 변화율이 큰 (dL/dW^2가 큰) 원소는 (1/√h가 작아서) W가 조금 바뀌고 L의 변화율이 작은 (dL/dW^2가 작은) 원소는 (1/√h가 작아서) W가 크게 바뀜 - 매개변수의 원소마다 학습률이 다르게 적용되고, W가 많이 바뀌어서 학습이 많이 된 원소는 학습률이 낮아짐
#AdaGrad
class AdaGrad:
def __init__(self, lr = 0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h == None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr*grads[key] / (np.sqrt(self.h[key]) +1e-7)
# 1e-7 : h[key]에 0이 있는 경우 0으로 나누는 것을 방지. 이 값도 설정 가능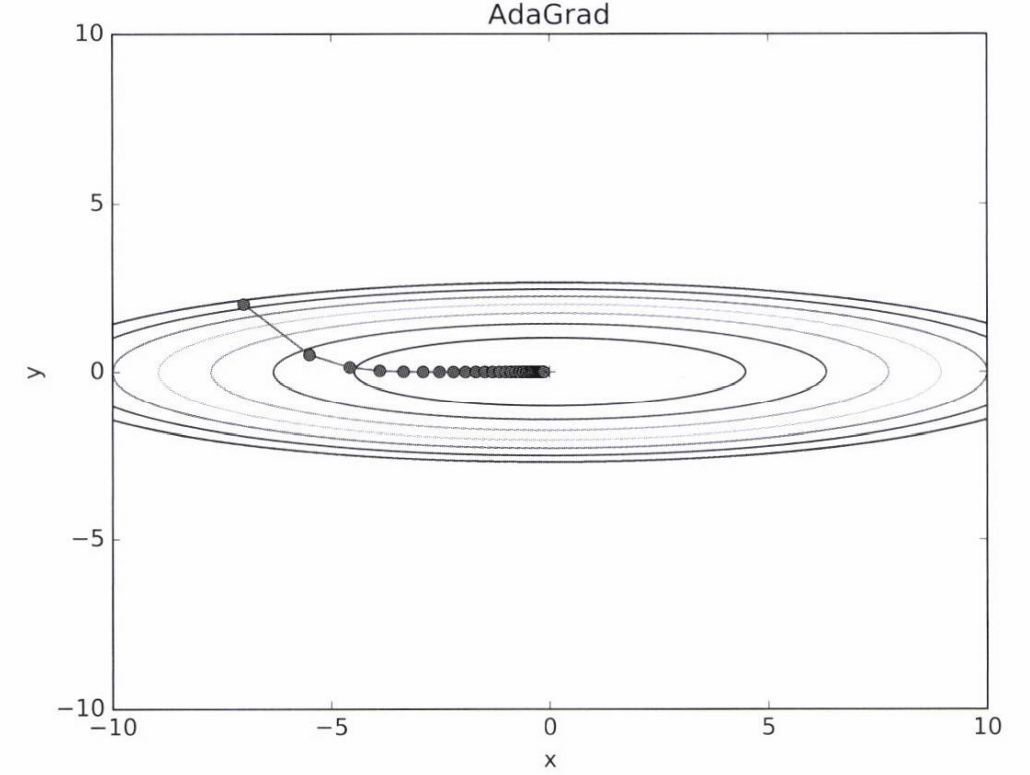
- 최솟값을 향해 효율적으로 움직임
- y축 방향은 기울기가 커서 처음에는 크게 움직이지만, 갱신 정도도 큰 폭으로 작아지도록 조정.
-> y축 방향으로 갱신 강도가 빠르게 약해지고, 지그재그 움직임이 줄어듬
6.1.6 Adam
- 모멘텀과 AdaGrad 기법 융합
- 매개변수 공간 효율적으로 탐색
- 하이퍼파라미터의 편향 보정 진행

- 모멘텀과 비슷한 패턴이지만 모멘텀 때보다 공의 좌우 흔들림이 적음
-> 학습의 갱신 강도를 적응적으로 조정하기 때문
6.1.7 어떤 갱신 방법을 이용할 것인가?
- 풀어야 할 문제가 무엇이냐에 따라 달라짐
- 하이퍼파라미터를 어떻게 설정하느냐에 따라서도 달라짐
- 모든 문제에서 항상 뛰어난 기법이라는 것은 아직 없음
- 일반적으로 SGD보다 다른 세 기법이 빠르게 학습하고, 때로는 최종 정확도도 높게 나타남
6.1.8 MNIST 데이터셋으로 본 갱신 방법 비교


- SGD의 학습 진도가 가장 느림
- 나머지 세 기법의 진도는 비슷, AdaGrad가 제일 빠름
- 하이퍼파라미터인 학습률과 신경마의 구조에 따라 결과 달라짐
6.2 가중치의 초깃값
6.2.1 초깃값을 0으로 하면?
가중치 감소 : 가중치 매개변수의 값이 작아지도록 학습하는 방법
가중치 값을 작게 하여 오버피팅이 일어나지 않게 함
- 가중치를 모두 0으로 하면 학습 제대로 x
- 가중치를 균일한 값으로 설정하면 안됨
오차역전파법에서 모든 가중치의 값이 똑같이 갱신되기 때문
=> 초깃값을 무작위로 설정해야 함
6.2.2 은닉층의 활성화값 분포
- 은닉층의 활성화값의 분포는 중요한 정보
- 가중치의 초깃값에 따라 은닉층 활성화값이 어떻게 변화하는지 실험
- 활성화 함수로 시그모이드 함수를 사용하는 5층 신경망에 무작위로 생성한 입력 데이터 흘림
- 각 층의 활성화값 분포를 히스토그램으로 그림
#은닉층의 활성화값 분포 실험
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.random.randn(1000, 100) #1000개의 입력 데이터 무작위로 생성
node_num = 100 #각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 #은닉층 개수
activations = {} #활성화 결과(활성화값) 저장
for i in range(hidden_layer_size):
if i !=0:
x = activations[i-1]
#w = np.random.randn(node_num, node_num)*1 #표준편차가 1인 정규분포 가중치
#w = np.random.randn(node_num, node_num)*0.01 #표준편차가 0.1인 정규분포 가중치
w = np.random.randn(node_num, node_num) / np.sqrt(node_num) #Xavier초깃값
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z
#히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
if i != 0: plt.yticks([], [])
# plt.xlim(0.1, 1)
# plt.ylim(0, 7000)
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()

- 표준편차1인 정규분포 가중치 - - 표준편차0.01인 정규분포 가중치 -
- 각 층의 활성화값들이 0과 1에 치우쳐 분포 0.5 부근에 집중
- 그 미분은 0에 다가가기 때문에 역전파의 기울기 값이 점점 작아짐 다수의 뉴런이 거의 같은 값을 출력
- 기울기 소실 문제 표현력 제한
=> 각 층의 활성화값은 고루 분포되어야 함
Xavier 초깃값
- 일반적인 딥러닝 프레임워크들이 표준적으로 이용
- 앞 계층의 노드가 n개라면 표준편차가 1/√n인 분포를 사용

- 넓게 분포되어 있음 -> 표현력 제한받지 않고 학습 효율적으로 가능
- tanh함수를 활성화함수로 사용하면 layer가 깊어질수록 모양 일그러지지 않음
- tanh함수는 원점(0.0)에서 대칭인 s곡선 (sigmoid는 0.05에서 대칭)
- 활성화 함수용으로는 원점에서 대칭인 함수가 바람직하다고 알려져 있음
6.2.3 ReLU를 사용할 때의 가중치 초깃값
- ReLU를 이용할 때는 He 초깃값 이용 권장
- He는 초깃값의 표준편차가 2/√n인 정규분포 사용 (음의 영역은 모두 0이기 때문에 더 넓게 분포시키기 위해)

- He 초깃값일 때만 모든 층에서 균일하게 분포
6.2.4 MNIST 데이터셋으로 본 가중치 초깃값 비교
# 0. MNIST 데이터 읽기==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1. 실험용 설정==========
weight_init_types = {'std=0.01': 0.01, 'Xavier': 'sigmoid', 'He': 'relu'}
optimizer = SGD(lr=0.01)
networks = {}
train_loss = {}
for key, weight_type in weight_init_types.items():
networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],
output_size=10, weight_init_std=weight_type)
train_loss[key] = []
# 2. 훈련 시작==========
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for key in weight_init_types.keys():
grads = networks[key].gradient(x_batch, t_batch)
optimizer.update(networks[key].params, grads)
loss = networks[key].loss(x_batch, t_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print("===========" + "iteration:" + str(i) + "===========")
for key in weight_init_types.keys():
loss = networks[key].loss(x_batch, t_batch)
print(key + ":" + str(loss))
# 3. 그래프 그리기==========
markers = {'std=0.01': 'o', 'Xavier': 's', 'He': 'D'}
x = np.arange(max_iterations)
for key in weight_init_types.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 2.5)
plt.legend()
plt.show()
- 층별 뉴런 수가 100개인 5층 신경망, 활성화 함수로 ReLU사용
- std = 0.01일 때는 학습 전혀 x
- He 학습 진도 가장 빠름
6.3 배치 정규화
- 각 층이 활성화값을 적당히 퍼뜨리도록 강제 -> 배치 정규화 (Batch Normalization)
6.3.1 배치 정규화 알고리즘
: 각 층에서 활성화값이 적당히 분포되도록 조정
- 배치 정규화 계층을 활성화 함수의 앞(혹은 뒤)에 삽입

주목받는 이유
- 학습을 빨리 진행할 수 있다 : 학습 속도 개선
- 초깃값에 크게 의존하지 않음
- 오버피팅을 억제 : 드롭아웃 등의 필요성 감소

- 학습 시 미니배치를 단위로 정규화
- 평균이 0, 분산이 1이 되도록 정규화
- 엡실론 : 작은 값 (10e-7) -> 0으로 나누는 사태 예방
- 배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대(γ, scale)와 이동(β, shift) 변환 수행
- 두 값은 처음에 각각 1, 0 으로 시작
- 학습하면서 적합한 값으로 조정
- 이유: 데이터를 계속 정규화 하게 되면 활성화 함수가 비선형의 역할을 상실하기 때문
- 활성화 결과로 평균이 0, 분산이 1인 값 (95%의 입력값은 x = -1.96 ~ 1.96의 값에 위치,이 때는 sigmoid가 선형)
- xi_hat이 scale과 shift를 거쳐서 sigmoid 함수의 선형이 아닌 부근에 위치하게 되면 활성화 결과가 비선형

6.3.2 배치 정규화의 효과
from common.multi_layer_net_extend import MultiLayerNetExtend
from common.optimizer import SGD, Adam
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 학습 데이터를 줄임
x_train = x_train[:1000]
t_train = t_train[:1000]
max_epochs = 20
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
def __train(weight_init_std):
bn_network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std, use_batchnorm=True)
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std)
optimizer = SGD(lr=learning_rate)
train_acc_list = []
bn_train_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch)
optimizer.update(_network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
bn_train_acc = bn_network.accuracy(x_train, t_train)
train_acc_list.append(train_acc)
bn_train_acc_list.append(bn_train_acc)
print("epoch:" + str(epoch_cnt) + " | " + str(train_acc) + " - " + str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
# 그래프 그리기==========
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
print( "============== " + str(i+1) + "/16" + " ==============")
train_acc_list, bn_train_acc_list = __train(w)
plt.subplot(4,4,i+1)
plt.title("W:" + str(w))
if i == 15:
plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)
plt.plot(x, train_acc_list, linestyle = "--", label='Normal(without BatchNorm)', markevery=2)
else:
plt.plot(x, bn_train_acc_list, markevery=2)
plt.plot(x, train_acc_list, linestyle="--", markevery=2)
plt.ylim(0, 1.0)
if i % 4:
plt.yticks([])
else:
plt.ylabel("accuracy")
if i < 12:
plt.xticks([])
else:
plt.xlabel("epochs")
plt.legend(loc='lower right')
plt.show()
=> 가중치 초깃값에 크게 의존하지 않음
=> 거의 모든 경우에서 배치 정규화를 사용할 때 학습 진도가 빠름
6.4 바른 학습을 위해
6.4.1 오버피팅
주로 다음의 두 경우에 일어남
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음
오버피팅 실험
- MNIST데이터셋 훈련 데이터 중 300개만 사용, 7층 네트워크로 복잡성 높임
- 각 층의 뉴런은 100개, 활성화 함수 ReLU
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 학습 데이터를 줄임
x_train = x_train[:300]
t_train = t_train[:300]
#훈련
network = MultiLayerNet(input_size=784, hidden_size_list = [100,100,100,100,100,100], output_size = 10)
optimizer = SGD(lr=0.01) #학습률이 0.01인 SGD로 매개변수 갱신
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = [] #에폭 단위의 정확도 저장
test_acc_list = []
iter_per_epoch = max(train_size/batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
optimizer.update(network.params, grads)
if i%iter_per_epoch ==0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt+=1
if epoch_cnt >= max_epochs:
break
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
- 훈련 데이터 정확도는 100 에폭을 지나는 무렵부터 거의 100%
- 시험 데이터 정확도와 큰 차이
-> 훈련 데이터에만 적응한 결과
6.4.2 가중치 감소
weight decay: 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 페널티를 부과하여 오버피팅을 억제하는 방법
- 손실함수에 L2 norm (1/2 * λ * W^2)를 더함
- λ 람다는 정규화의 세기를 조절하는 하이퍼파라미터

-> 훈련 데이터와 시험 데이터에 대한 정확도 차이 줄음 => 오버피팅 억제
-> 훈련 데이터에 대한 정확도가 100%에 도달하지 않음
6.4.3 드롭아웃
: 뉴런을 임의로 삭제하면서 학습하는 방법
- 훈련 때는 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택
- 시험 때는 모든 뉴런에 신호를 전달
- 시험 때는 각 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱하여 출력 (생략)

#드롭아웃
class Dropout:
def __init__(self, dropout_ratio = 0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio #x와 형상이 같은 배열을 무작위로 생성, 그 값이 dropout_ration보다 큰 원소만 True
return x*self.mask
else:
return x*(1.0-self.dropout_ratio)
def backward(self, dout):
return dout * self.mask- 순전파 때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 통과시킴
- 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호 차단
- forward pass를 할 때마다 dropout되는 노드는 임의로 바뀌기 때문에 학습에 큰 영향을 미치는 노드 이외의 다른 노드들에 대해서도 학습이 더 잘 돼서 overfitting이 줄어듬.
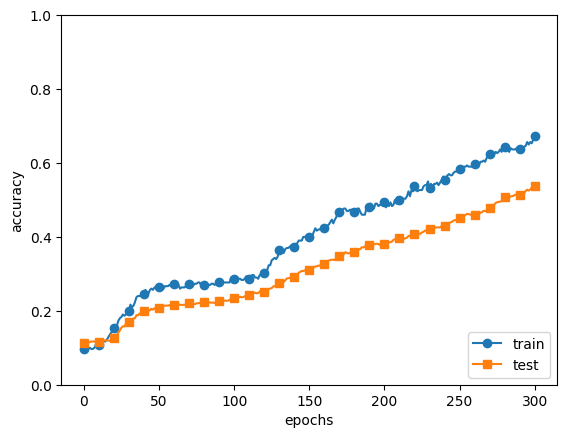
- 훈련 데이터와 시험 데이터에 대한 정확도 차이 줄음
- 훈련 데이터에 대한 정확도 100% 아님
-> 표현력을 높이면서 오버피팅 억제 - 앙상블 학습 효과
- 앙상블 : 개별적으로 학습시킨 여러 모델의 출력을 평균 내어 추론하는 방식
- 드롭아웃 : 학습 때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석
6.5 적절한 하이퍼파라미터 값 찾기
6.5.1 검증 데이터
- 하이퍼파라미터의 성능을 평가할 때는 시험 데이터를 사용하면 안됨
- 하이퍼파라미터 값이 시험 데이터에 오버피팅되기 때문
- 하이퍼파라미터 전용 확인 데이터 필요 -> 검증 데이터 (validation data)
- 훈련 데이터 : 매개변수 학습
- 검증 데이터 : 하이퍼파라미터 성능 평가
- 시험 데이터 : 신경망의 범용 성능 평가
#MNIST 데이터셋에서 검증 데이터 얻기
(x_train, t_train), (x_test, t_test) = load_mnist()
#훈련 데이터 뒤섞기
x_train, t_train = shuffle_dataset(x_train, t_train)
#20%를 검증 데이터로 분할
validation_rate = 0.20
validation_num = int(x_train.shape[0]*validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = x_train[validation_num:]
6.5.2 하이퍼파라미터 최적화
: 하이퍼파라미터의 '최적 값'이 존재하는 범위를 조금씩 줄여나감
0단계 : 대략적인 범위 설정 (로그 스케일로 지정, ex) 0.001에서 1000사이)
1단계 : 무작위로 하이퍼파라미터 값을 샘플링(추출)
2단계 : 그 값으로 정확도 평가 (에폭은 작게 설정-1회 평가에 걸리는 시간 단축 위해)
3단계 : 정확도 결과로 범위 좁히기, 반복
6.5.2 하이퍼파라미터 최적화 구현하기
#하이퍼파라미터 최적화 구현
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 결과를 빠르게 얻기 위해 훈련 데이터를 줄임
x_train = x_train[:500]
t_train = t_train[:500]
# 20%를 검증 데이터로 분할
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
def __train(lr, weight_decay, epocs=50):
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,
epochs=epocs, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)
trainer.train()
return trainer.test_acc_list, trainer.train_acc_list
# 하이퍼파라미터 무작위 탐색======================================
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
# 탐색할 하이퍼파라미터의 범위 지정===============
weight_decay = 10 ** np.random.uniform(-8, -4) #가중치 감소 세기 계수, 범위(10^-8 ~10^-4)
lr = 10 ** np.random.uniform(-6, -2) #학습률, 범위(10^-6~10^-2)
# ================================================
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
# 그래프 그리기========================================================
print("=========== Hyper-Parameter Optimization Result ===========")
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0
for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):
print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)
plt.subplot(row_num, col_num, i+1)
plt.title("Best-" + str(i+1))
plt.ylim(0.0, 1.0)
if i % 5: plt.yticks([])
plt.xticks([])
x = np.arange(len(val_acc_list))
plt.plot(x, val_acc_list)
plt.plot(x, results_train[key], "--")
i += 1
if i >= graph_draw_num:
break
plt.show()- 하이퍼파라미터 검증 범위 0.001~1000 사이에서 무작위 추출 : 10**np.random.uniform(-3,3)
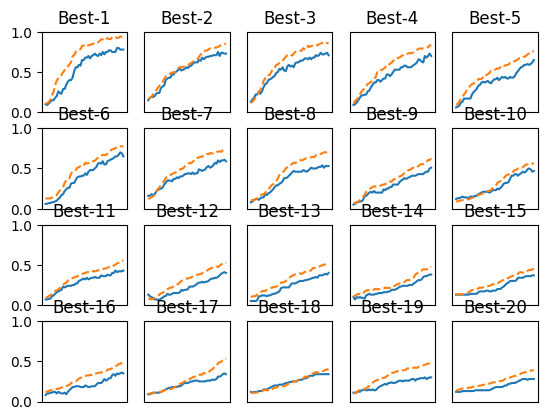
- 검증 데이터의 학습 추이를 정확도가 높은 순서로 나열
- Best-5정도까지 학습이 순조로움
- Best-1(val acc:0.78) | lr:0.009976648137882835, weight decay:2.8454240859987083e-07
- Best-2(val acc:0.73) | lr:0.006884034990967694, weight decay:1.1844772320662975e-06
- Best-3(val acc:0.71) | lr:0.005829457100402598, weight decay:3.3344298206917275e-07
- Best-4(val acc:0.7) | lr:0.00535950774058873, weight decay:1.505493479471236e-06
- Best-5(val acc:0.65) | lr:0.0045251758231664545, weight decay:3.4950414167758566e-08
-> 학습이 잘 진행될 때의 범위를 관찰하고 좁혀나감 -> 반복 -> 특정 단계에서 최종 하이퍼파라미터 값 하나 선택
6.6 정리
- 매개변수 갱신 방법에는 확률적 경사 하강법(SGD) 외에도 모멘텀, AdaGrad, Adam 등이 있다.
- 가중치 초깃값을 정하는 방법은 올바른 학습을 하는 데 매우 중요하다.
- Xavier 초깃값과 He 초깃값(ReLu함수)이 효과적
- 배치 정규화를 이용하면 학습을 빠르게 진행할 수 있으며, 초깃값에 영향을 덜 받게 됨
- 오버피팅을 억제하는 정규화 기술로는 가중치 감소와 드롭아웃이 있다.
- 하이퍼파라미터 값 탐색은 최적 값이 존재할 법한 범위를 점차 좁히면서 하는 것이 효과적
책 참고 : 밑바닥부터 시작하는 딥러닝 (한빛미디어)
'딥러닝 > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| 8장 : 딥러닝 (0) | 2023.09.19 |
|---|---|
| 7장 : 합성곱 신경망(CNN) (0) | 2023.09.17 |
| 5장 : 오차역전파법 (0) | 2023.09.13 |
| 4장 : 신경망 학습 (0) | 2023.09.06 |
| 3장 : 신경망 (0) | 2023.09.05 |



