7.1 언어 모델을 사용한 문장 생성
7.1.1 RNN을 사용한 문장 생성의 순서
- 'I' 라는 단어를 입력으로 주면 다음에 출현하는 단어의 확률분포를 출력함
- 이 결과를 기초로 다음 단어를 새로 생성하려면
1) 확률이 가장 높은 단어를 선택하는 방법 - 결정적
결정적 : 결과가 일정하게 정해지는 것
2) 확률적으로 선택하는 방법
각 후보 단어의 확률에 맞게 선택하는 것, 확률이 높은 단어는 선택되기 쉽고, 낮은 단어는 선택되기 어려움
선택되는 단어(샘플링 단어)가 매번 다를 수 있음

7.1.2 문장 생성 구현
##RnnlmGen 클래스 구현
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
#statr_id : 최초로 주는 단어의 ID, sample_size : 샘플링하는 단어의 수
#skip_ids : 샘플링되지 않도록 하는 단어ID 리스트 (<unk>, N등 전처리된 단어)
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1,1) #2차원 배열로 성형(미니배치 처리 위해)
score = self.predict(x) #각 단어의 점수 출력
p = softmax(score.flatten())
sampled = np.random.choice(len(p), size=1, p=p) #p대로 샘플링
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids##문장 생성 코드
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('/content/drive/MyDrive/Colab Notebooks/밑바닥딥러닝2/Rnnlm.pkl') #앞장에서 학습한 가중치 매개변수 사용
#시작(start)문자와 건너뜀(skip) 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
#문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids]) #word사이에 공백 삽입해 모두 연결
txt = txt.replace(' <eos> ', '.\n')
print(txt)you can consider the positions that could now do when one is a good market can take wins required in a remarkable calculated when the skin hand in some of the industry says no rash of its own movement mengistu.
minicomputers by mr. lawrence said the events has never completely say.
his personal deployed would have quickly done costs for a european exchanges and services.
hope of potentially buying he is going to increase their problems.
a bidding premium from being determined by drexel burnham lambert inc.
that imports was n't traded as similar explosion-> 아직 개선 여지 남아있음
7.1.3 더 좋은 문장으로
- 앞장에서 개선한 BetterRnnlm 모델로 학습한 가중치 매개변수 사용
##BetterRnnlmGen클래스 구현
class BetterRnnlmGen(BetterRnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x).flatten()
p = softmax(score).flatten()
sampled = np.random.choice(len(p), size=1, p=p)
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_ids
def get_state(self):
states = []
for layer in self.lstm_layers:
states.append((layer.h, layer.c))
return states
def set_state(self, states):
for layer, state in zip(self.lstm_layers, states):
layer.set_state(*state)##문장 생성 코드
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = BetterRnnlmGen()
model.load_params('/content/drive/MyDrive/Colab Notebooks/밑바닥딥러닝2/BetterRnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)
##the meaning of lige is 실험
model.reset_state()
start_words = 'the meaning of life is'
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x) #the~life까지 순전파 수행
word_ids = model.generate(start_ids[-1], skip_ids) #is 첫단어로 문장 생성
word_ids = start_ids[:-1] + word_ids
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print('-' * 50)
print(txt)-> 저번보다 자연스러운 문장
you will require it during the next few weeks transportation.
i 've n't said william exclusive a person remain has hampered side in westmoreland on heart for their own.
mr. evaluating and payouts the spot stood at more than the famous discussion of most subordinate fund tuesday to be complete with a small aichi program.
but east germany has a type of col. butler it ever was investigators.
but it they read discussions with mr. lawson in a new embassy he consistently contributed in a proposal helicopter.
it is still concerned that u.s. car executives
--------------------------------------------------
the meaning of life is often far in any or more several business of hud 's risk in the mercury.
in poland the general refinery of legislation officials said earlier this year the tall wealthy embryo grew to old center lie.
the key party in about five years earlier philip burnham lambert 's national product.
a par shot for senate bosses and toy entered computing bars manufacturers ' activities into wholesale market spending and a key extra if the risks and japan probably holdings throughout a while earthquakes.
it is either less big information hundreds of drug auctions mr. engelken책 : the meaning of life is not a good version of paintings
7.2 seq2seq
- 시계열 데이터를 또 다른 시계열 데이터로 변환하는 문제
- 기계 번역
- 음성 인식
- 챗봇
7.2.1 seq2seq의 원리
- Encoder-Decoder 모델
- Encoder : 입력 데이터를 인코딩 (부호화 : A -> 1000001 )
- Decoder : 입코딩된 데이터를 디코딩 (복호화 : 1000001-> A)

- Encoder가 인코딩한 정보에는 번역에 필요한 정보가 조밀하게 응축되어 있음
- Decoder는 조밀하게 응축된 이 정보를 바탕으로 도착어 문장을 생성Encoder가 출력하는 벡터 h는 LSTM 계층의 마지막 은닉 상태
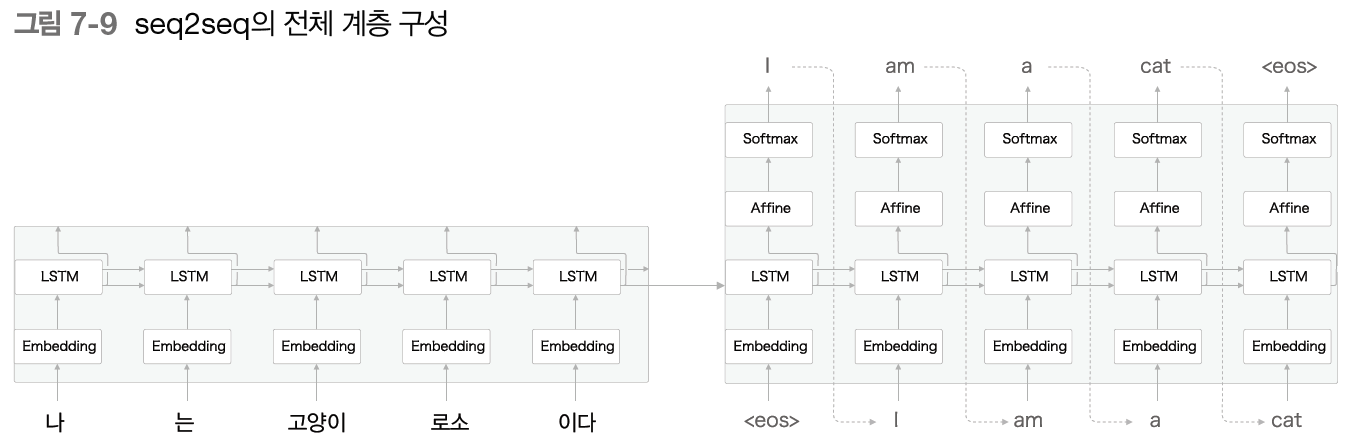
- 이 h에 입력 문장을 번역하는 데 필요한 정보가 인코딩
- h : 고정길이 벡터
- 인코딩 - > 임의 길이의 문장을 고정 길이 벡터로 변환하는 작업
- Decoder는 LSTM과 완전 같은 구성
- LSTM계층이 벡터 h를 입력받는다는 점 빼고 모두 같음
- <eos> : 구분자, 문장 생성의 시작과 종료를 알리는 신호
7.2.2 시계열 데이터 변환용 장난감 문제
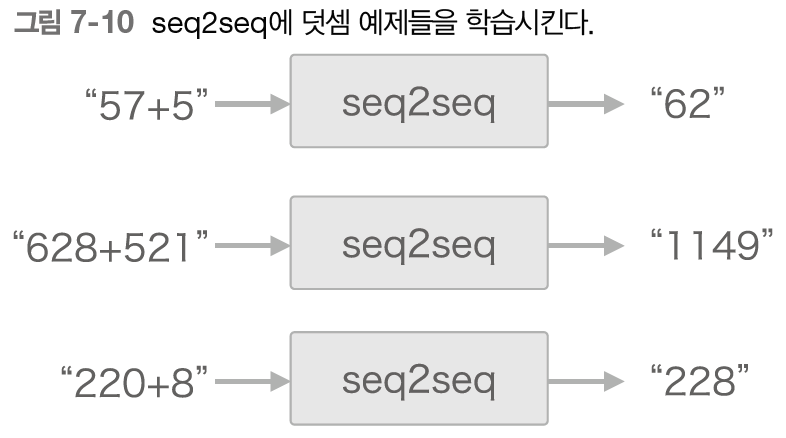
- 덧셈 규칙을 학습 시킴
- 단어가 아닌 문자 단위로 분할 (5, 7, +, 5)
7.2.3 가변 길이 시계열 데이터
- 샘플마다 데이터의 시간 방향 크기가 다름 -> 가변 길이 시계열 데이터
- 미니배치 처리를 위해서는 샘플들의 데이터 형상이 모두 같아야 함
-> 패딩 사용
- 패딩 : 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법
- 모든 입력 데이터의 길이를 통일, 남는 공간에는 의미 없는 데이터를 채움

- 0~999사이의 숫자 2개만 더하기
- 입력의 최대 문자 수 : 7
- 출력의 최대 문자 수 : 5 (질문과 정답을 구분하기 위해 출력 앞에 구분자 밑줄(_) 추가)
- 패딩 전용 처리 (이번 장에서는 다루지 않음)
- Decoder- 입력된 데이터가 패딩이라면 손실의 결과에 반영되지 않도록 softmaxwithLoss계층에 마스크 기능 추가
- Encoder-입력된 데이터가 패딩이라면 LSTM계층이 이전 시각의 입력을 그대로 출력
-> 패딩이 존재하지 않았던 것처럼 인코딩
7.2.4 덧셈 데이터셋
from dataset import sequence
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt', seed=1994)
#load_data메소드 : 텍스트 파일을 읽어 텍스트를 문자 ID로 변환, 이를 훈련데이터와 테스트 데이터로 나눠 반환
#seed : 메소드 내부에서 사용하는 무작위수의 초깃값
char_to_id, id_to_char = sequence.get_vocab()
#get_vocab메소드 : 문자와 문자ID의 대응 관계를 담은 딕셔너리 반환
print(x_train.shape, t_train.shape) #(45000, 7) (45000, 5)
print(x_test.shape, t_test.shape) #(5000, 7) (5000, 5)
print(x_train[0]) #[10 0 2 1 0 3 5] -> 문자 ID 형태
print(t_train[0]) #[ 6 1 12 11 5]
print(''.join([id_to_char[c] for c in x_train[0]])) #31+617
print(''.join([id_to_char[c] for c in t_train[0]])) #_6487.3 seq2seq 구현
7.3.1 Encoder 클래스

- Embedding 계층 - 문자ID를 문자 벡터로 변환 -> LSTM으로 입력
- LSTM계층 - 오른쪽으로는 은닉 상태와 셀을 출력, 위쪽으로는 은닉 상태만 출력 -> 위쪽 출력은 폐기
- 마지막 문자를 처리한 후 LSTM계층의 은닉 상태 h 출력 -> Decoder로 전달
class Encoder:
def __init__(self, vocab_size, word2vec_size, hidden_size):
#vocab_size : 어휘 수(문자의 종류)
V, D, H = vocab_size, word2vec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D)/100).astype('f')
lstm_Wx = (rn(D, 4*H)/ np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H)/ np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False) #상태 유지하지 않기 때문에 stateful=false
self.params = self.embed.params +self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :] #마지막 시각의 은닉 상태
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
7.3.2 Decoder 클래스
- Encoder에서 h를 받아 다른 문자열 출력
- 이번 문제는 덧셈이므로 확률적인 비결정성 배제하고 결정적인 답 생성
- 확률적 -> 결정적 => argmax 노드

- argmax 노드 : 최댓값을 가진 원소의 인덱스를 선택하는 노드
- Sofrmax계층 사용하지 않고 Affine계층이 출력하는 점수가 가장 큰 문자 ID 선택
- Softmax 계층 : 입력된 벡터를 정규화, 대소 관계는 바뀌지 않음
class Decoder:
def __init__(self, vocab_size, word2vec_size, hidden_size):
#vocab_size : 어휘 수(문자의 종류)
V, D, H = vocab_size, word2vec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D)/100).astype('f')
lstm_Wx = (rn(D, 4*H)/ np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4*H)/ np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
#decoder에서는 stateful = True, 인코더의 h 유지하면서 순전파
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += self.params
self.grads += self.grads
def forward(self, xs, h): #학습에 사용
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size): #문장 생성
sampled=[]
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1,1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
#Affine계층이 출력하는 점수가 가장 큰 id 선택
sampled.append(int(sample_id))
return sampled
7.3.3 Seq2seq 클래스
Encoder와 Decoder 연결, 손실 계산
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params +self.decoder.params
self.grads = self.encoder.grads +self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
7.3.4 seq2seq 평가
- seq2seq 학습
- 1. 학습 데이터에서 미니배치 선택
- 2. 미니배치로부터 기울기 계산
- 3. 기울기를 사용하여 매개변수 갱신
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
#from peeky_seq2seq import PeekySeq2seq
#데이터셋 읽기
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
#하이퍼파라미터 설정
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
# 입력 반전 여부 설정
is_reverse = False # True
if is_reverse:
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
#모델 / 옵티마이저 / 트레이너 생성
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = [] #평가 척도로 정답률 사용
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1, batch_size = batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10 #테스트데이터 최초 10개 표시
correct_num += eval_seq2seq(model, question, correct, id_to_char, verbose, is_reverse)
#eval_seq2seq함수의 인수 1)moder, 2)question(문제문장) 3)correct_id(정답) 4)id_to_char(문자ID와 문자의 변환 수행)
#5)verbose(True로 설정하면 결과를 터미널로 출력) 6)is_reverse(입력 데이터 반전)
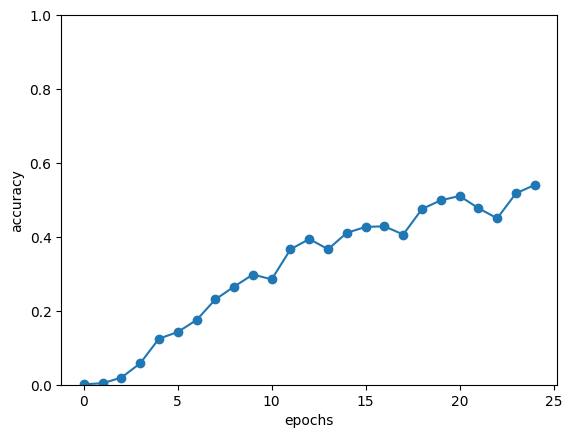
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('검증 정확도 %.3f%%' %(acc*100))
# 그래프 그리기
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()

-> 학습을 거듭할수록 정답에 가까워지면서, 몇 개씩은 맞히게 됨
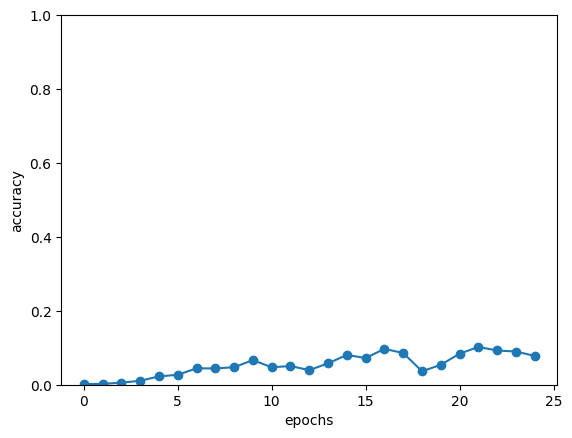
-> 정답률 에폭 거듭할수록 개선됨
7.4 seq2seq 개선
7.4.1 입력 데이터 반전(Reverse)
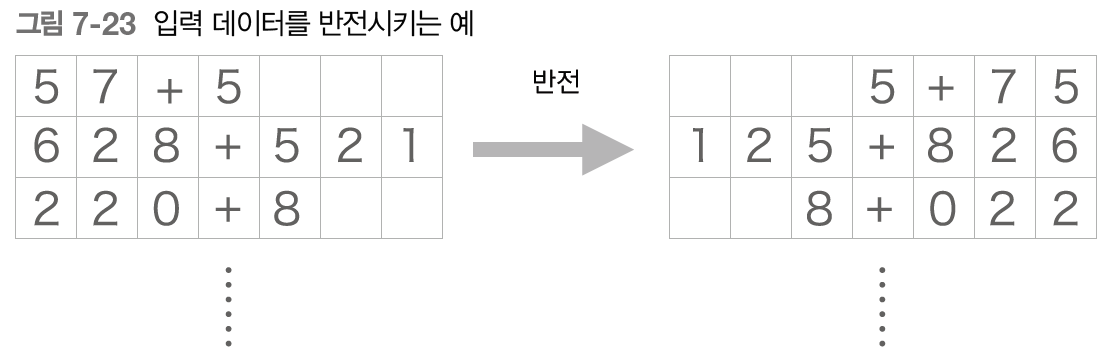
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]- [::-1]인덱스 호출 ->반전된 결과 반환
- 기울기 전파가 원활해지기 때문에 정확도 향상됨
- 입력 문장의 첫 부분 반전하면 출력 해야하는 단어와 가까워짐
- 기울기가 더 잘 전달됨
7.4.2 엿보기(Peeky)
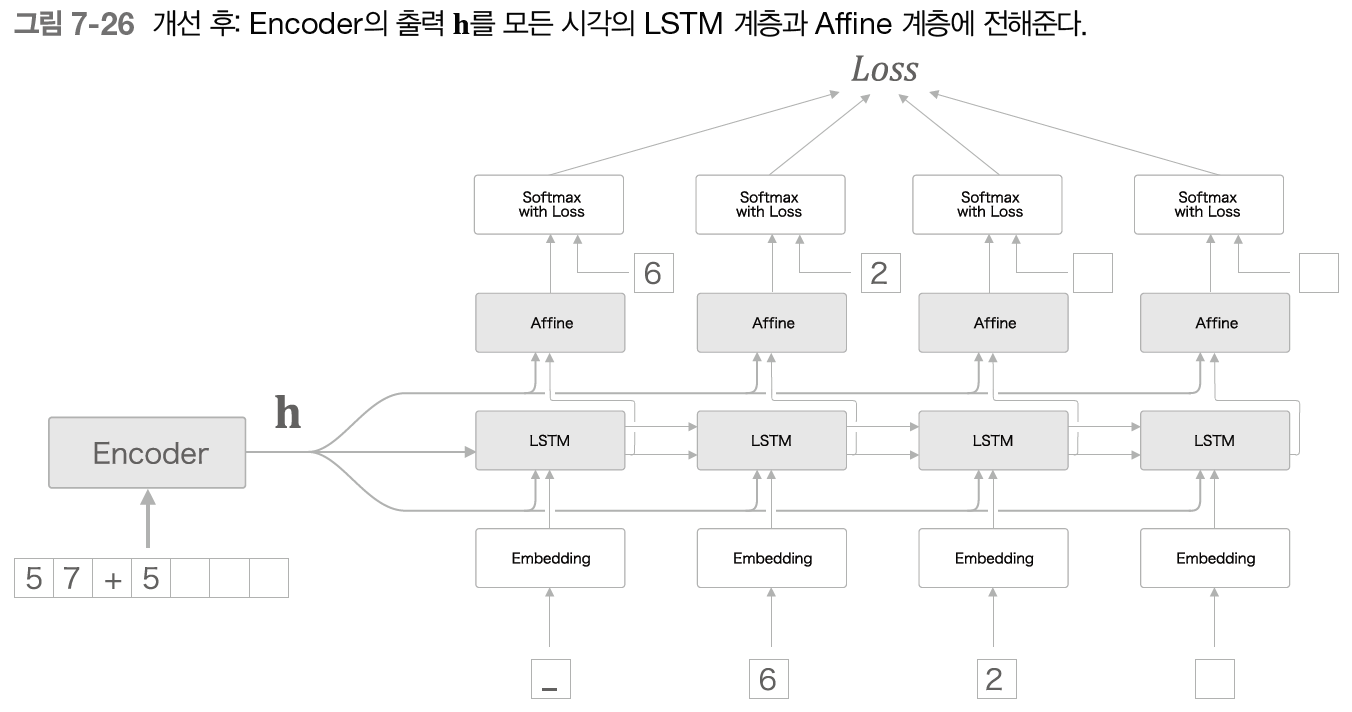
- 중요한 정보가 담긴 Encoder의 출력 h를 Decoder의 다른 계층에도 전해주는 것
- 원래는 최초 시각의 LSTM계층만이 이용
- 모든 시각의 Affine계층과 LSTM계층에 h 전달
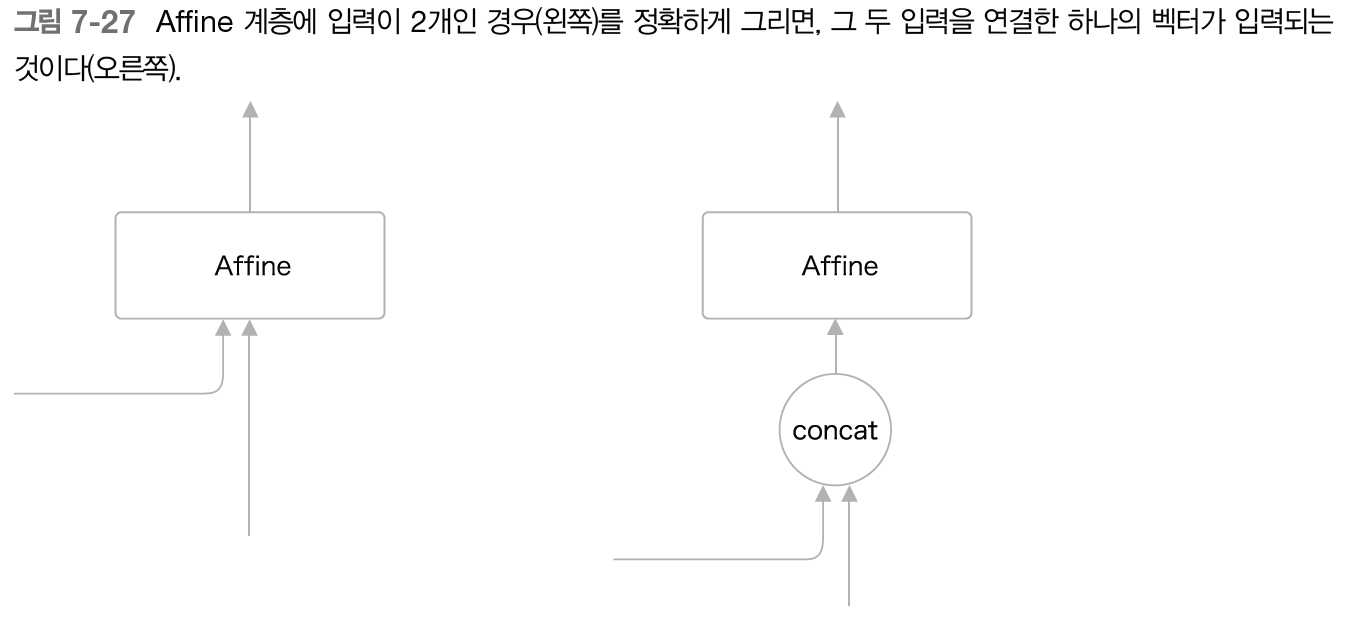
- Affine계층과 LSTM계층에 입력되는 벡터 2개가 됨 -> 실제로는 두 벡터가 연결 concatenate
class peekyDecoder:
def __init__(self, vocab_size, word2vec_size, hidden_size):
#vocab_size : 어휘 수(문자의 종류)
V, D, H = vocab_size, word2vec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D)/100).astype('f')
lstm_Wx = (rn(H+D, 4*H)/ np.sqrt(D)).astype('f') #H가 더해짐
lstm_Wh = (rn(H, 4*H)/ np.sqrt(H)).astype('f')
lstm_b = np.zeros(4*H).astype('f')
affine_W = (rn(H+H, V) / np.sqrt(H)).astype('f') #H가 더해짐
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
#decoder에서는 stateful = True, 인코더의 h 유지하면서 순전파
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += self.params
self.grads += self.grads
self.cache = None
def forward(self, xs, h): #학습에 사용
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H) #h를 시계열만큼 복제
out = np.concatenate((hs, out), axis=2) #hs와 Embedding계층 출력 연결
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2) #hs와 lstm계층 출력 연결
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampled
class PeekySeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = PeekyDecoder(V, D, H) #peekydecoder사용
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads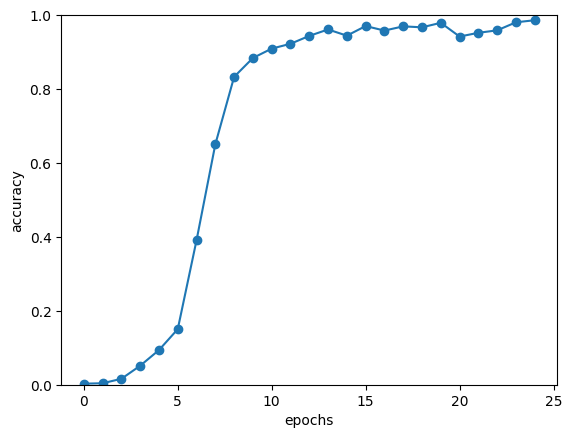
7.5 seq2seq를 이용하는 애플리케이션
seq2seq는 한 시계열 데이터를 다른 시계열 데이터로 변환
- 다양한 문제에 적용 가능
- 기계 번역
- 자동 요약
- 질의응답
- 메일 자동 응답
7.5.1 챗봇

7.5.2 알고리즘 학습

7.5.3 이미지 캡셔닝
- 텍스트 외에도 이미지나 음성 등 다양한 데이터 처리 가능
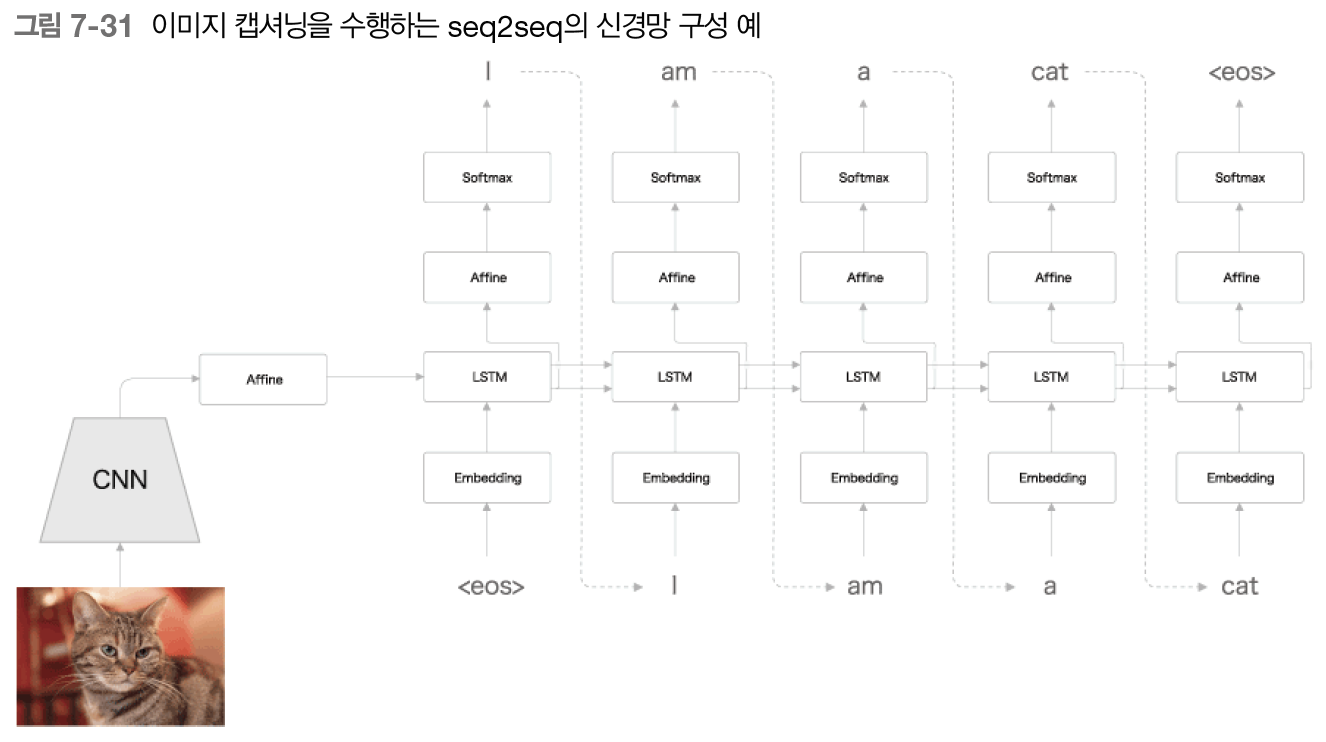
- Encoder를 LSTM에서 CNN (합성곱 신경망)으로 바꿈
7.6 정리
- RNN을 이용한 언어 모델은 새로운 문장을 생성할 수 있다.
- 문장을 생성할 때는 하나의 단어를 주고 모델의 출력(확률분포)에서 샘플링하는 과정을 반복한다.
- RNN을 2개 조합함으로써 시계열 데이터를 다른 시계열 데이터로 변환할 수 있다.
- seq2seq는 Encoder가 출발어 입력문을 인코딩하고, 인코딩된 정보를 Decoder가 받아 디코딩하여 도착어 출력문을 얻는다.
- 입력문을 반전시키는 기법(Reverse), 또는 인코딩된 정보를 Decoder의 여러 계층에 전달하는 기법(Peeky)은 seq2seq의 정확도 향상에 효과적이다.
- 기계번역, 챗봇, 이미지 캡셔닝 등 seq2seq는 다양한 애플리케이션에 이용할 수 있다.
책 참고 : 밑바닥부터 시작하는 딥러닝 (한빛미디어)
'딥러닝 > 밑바닥부터 시작하는 딥러닝 2' 카테고리의 다른 글
| 8장 : 어텐션 (1) | 2023.09.28 |
|---|---|
| 6장 : 게이트가 추가된 RNN (0) | 2023.09.26 |
| 5장 : 순환 신경망(RNN) (0) | 2023.09.26 |
| 4장 : word2vec 속도 개선 (0) | 2023.09.23 |
| 3장 : word2vec (0) | 2023.09.21 |



