논문: https://arxiv.org/abs/1503.08895v5
Abstract
구조 : a form of Memory Network, trained ene-to-end, an extension of RNNsearch,
multiple computational steps(hops)-> improved results
task : question answering, language modeling
* Memory network
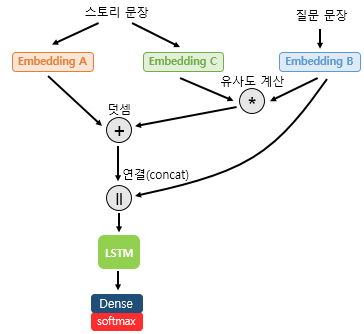
(1) 스토리 문장 Embedding C로 임베딩, 질문 문장 Embedding B로 임베딩 -> 내적을 통해 각 단어 간 유사도 -> 소프트맥스 함수
(2) 스토리 문장 Embedding A로 임베딩 -> 유사도와 덧셈 (어텐션 메커니즘) => 질문 문장과의 유사도를 반영한 스토리 문장 표현
(3) 질문 문장 임베딩한 질문 표현과 Concat -> LSTM과 밀집층(dense layer)의 입력으로 사용 -> 정답 예측
* * Attention
디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고
단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 참고

(1) 주어진 '쿼리(Query)'에 대해서 모든 '키(Key)'와의 유사도를 각각 구한다.
(2) 그리고 이 유사도를 가중치로 하여 키와 맵핑되어있는 각각의 '값(Value)'에 반영한다.
그리고 유사도가 반영된 '값(Value)'을 모두 가중합하여 리턴한다.
*** Dot-Product Attention

1) attention score (초록 원)
현재 디코더의 시점 t에서 단어 예측 위해
인코더의 모든 은닉 상태 각각(hi)이
디코더의 현 시점 은닉 상태St와
얼마나 유사한지 판단
-> 각 은닉 상태와 St 내적
2)Attention Distribution (빨간 분포)
어텐션 스코어의 모음 값에 소프트맥스 함수 적용
-> 모든 값 합하면 1이 되는 확률 분포
-> 어텐션 가중치
3)Attention Value
각 인코더의 은닉 상태와 어텐션 가중치값들을 가중합
-> 어텐션의 최종결과 : 어텐션 값

4) 어텐션 값과 디코더의 t 시점 은닉 상태 (St) 연결
-> 예측 연산의 입력으로 사용하므로서 인코더로부터 얻은 정보를 활용하여 예측 성능 올라감
* RNN
순환 신경망 : 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향했던 피드 포워드 신경망과는 달리 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징

은닉층의 메모리 셀은 각각의 시점에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값(은닉 상태값)을 자신의 입력으로 사용하는 재귀적 활동
* QA task
: 주어진 질문에 대한 text에서 답을 추출하는 것
input: 질문 sentence , text (paragraph)
한국외대의 위치는?
한국외국어대학교는 대한민국의 ~~~~~~~~~~이다.
~~~~~~~~~ 이며 서울 동대문구에 위치해 있다.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
output: 질문에 대한 답을 포함하는 text의 sentence
~~~~~~~~~~서울 동대문구에 위치해 있다.
* Language modeling task
주어진 문맥을 활용해 다음 단어를 예측
오늘은 -> 날씨가 -> ?
Introduction
Two grand challenges
1) multiple computational steps in the completing a task
2) Long dependency in sequential data
-> attention 개념, 부가적인 storage 도입
=> end to end로 학습, 기존의 모델보다 unsupervised한 성격의 모델
Approach
- Single Layer

Input memory representation
(1) input Xi - mi로 storage에 저장 - Embedding matrix A
(1) Question (query) - Enbedding matrix B - internal state u
(2) 각각의 mi 와 u 곱한 후 softmax (각 sentence와 query질문 의 연관성 계산)
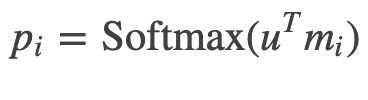
Ouput memory representation
(1) input Xi - Embedding matrix C
(2) Pi와 output vecter(c) 가중평균 -> 최종 response
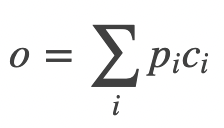
* attention
Generating the final prediction
(1) 질문 벡터 embedding 한 u + o
(2) 가중치 행렬 W(o+u)
(3) 소프트 맥스함수

총 4개의 parameter matrix A,B,C,W가 있고 학습의 경우 prediction 값인 â 와 실제 label a를 비교한
cross-entropy loss 함수를 사용하고 update는 SGD를 사용
- Multiple Layers
위의 layer를 K개 쌓음

* 첫 번째 layer를 제외한 layer의 질문(query) 벡터
이전 layer의 output vector인 o와 query vector 인 u를 더한 값을 사용

* 각 layer는 모두 다른 embedding matrix A,C를 사용

* parameter를 줄이기 위한 방법
(1) Adjacent : 인접한 embedding matrix를 같은 weight를 사용하게 함으로써 paramter 수를 줄이는 방법

(2) Layer-wise(RNN-like) : A와 C들이 각각 모두 같은 matrix를 사용

이 경우, 추가적인 linear mapping 함수 H 사용

참고자료:
'딥러닝 > Paper review' 카테고리의 다른 글
| [논문리뷰] Time is Encoded in the Weights of Finetuned Language Models (0) | 2024.04.30 |
|---|---|
| [논문리뷰] Towards Large Language Models as Copilots for Theorem Proving in Lean (0) | 2024.02.22 |